
Forschung
Entwicklung von Algorithmen zur Detektion von Schnarchgeräuschen
Wieso werden Schnarchgeräusche erforscht?
Das Schnarchen stellt ein weit verbreitetes Phänomen dar, das sowohl medizinische als auch soziale Relevanz besitzt. Aus gesundheitlicher Sicht ist besonders bedeutsam, dass Schnarchen ein Symptom für schwerwiegendere Störungen wie die obstruktive Schlafapnoe (OSA) sein kann, bei der es zu wiederholten Atemaussetzern während des Schlafs kommt. Diese Atemstörungen können das Risiko für Herz-Kreislauf-Erkrankungen erhöhen und die Lebensqualität erheblich beeinträchtigen. Zudem wird Schnarchen häufig als störend empfunden und kann zu Schlafmangel, Tagesmüdigkeit oder weiteren Problemen führen. Aus diesen Gründen ist die wissenschaftliche Erforschung des Schnarchens von großer Bedeutung, um Ursachen, Diagnosemöglichkeiten und Therapien weiter zu verbessern.
Forschung zur Echtzeitdetektion von Schnarchgeräuschen mittels neuronaler Netze
Aktuell befassen wir uns in unserer Forschung mit der Entwicklung und Evaluierung verschiedener Methoden sowie künstlicher neuronaler Netze zur Echtzeitdetektion von Schnarchgeräuschen. Im Rahmen dieses Vorhabens setzen wir uns intensiv mit den typischen Herausforderungen des maschinellen Lernens auseinander. Dazu zählen insbesondere die sorgfältige Auswahl, Aufbereitung und Kuratierung geeigneter Datensätze für das Training der Modelle sowie die Konzeption und Optimierung der Netzwerkarchitekturen selbst. Ziel ist es, robuste und zuverlässige Systeme zu entwickeln, die Schnarchgeräusche unter realen Bedingungen präzise und effizient erkennen können.
Anwendungsmöglichkeiten und Nutzen der Schnarchgeräuschdetektion in Echtzeitsystemen
Ein trainiertes neuronales Netz sowie die entwickelten Algorithmen zur Detektion von Schnarchgeräuschen ermöglichen die Realisierung vielfältiger Echtzeitanwendungen. In Kombination mit Verfahren zur automatisierten Erkennung einer obstruktiven Schlafapnoe (OSA) kann das System maßgeblich dazu beitragen, zwischen gewöhnlichen Schnarchgeräuschen und Anzeichen einer OSA zu differenzieren. Darüber hinaus eröffnet die präzise Detektion von Schnarchgeräuschen neue Möglichkeiten bei der gezielten Maskierung störender Geräusche, ohne dabei andere relevante akustische Signale – wie etwa Weckertöne oder eingehende Anrufe – zu unterdrücken. Dies kann insbesondere für betroffene Personen einen bedeutenden Zugewinn an Schlafqualität und Alltagstauglichkeit darstellen.
Audiocodierungsstrategien für Cochlea-Implantate
Hintergrund
Das Cochlea-Implantat (CI) ist eine elektronische Innenohrprothese, die es gehörlosen oder ertaubten Menschen ermöglicht, erstmals ein Hörvermögen zu erlangen oder wiederzuerlangen. Das Alter der Patienten reicht vom Kleinkind bis hin zum hohen Erwachsenalter und bringt für die behandelten Personen eine enorme Verbesserung der Lebensqualität mit sich [1, 2]. Cochlea-Implantate sind allerdings noch nicht geeignet, die Probleme aller Alltagssituationen zu meistern. Die Qualität des Hörerlebnisses für Musik oder in lauten Umgebungen ist stark eingeschränkt. Auch ein Richtungshören ist nicht immer möglich. Um diese Aspekte des CIs berücksichtigen zu können, wird weiter an Verbesserungsmöglichkeiten in Software und Hardware des Implantats geforscht.

Aufbau und Funktionsweise eines Cochlea-Implantats
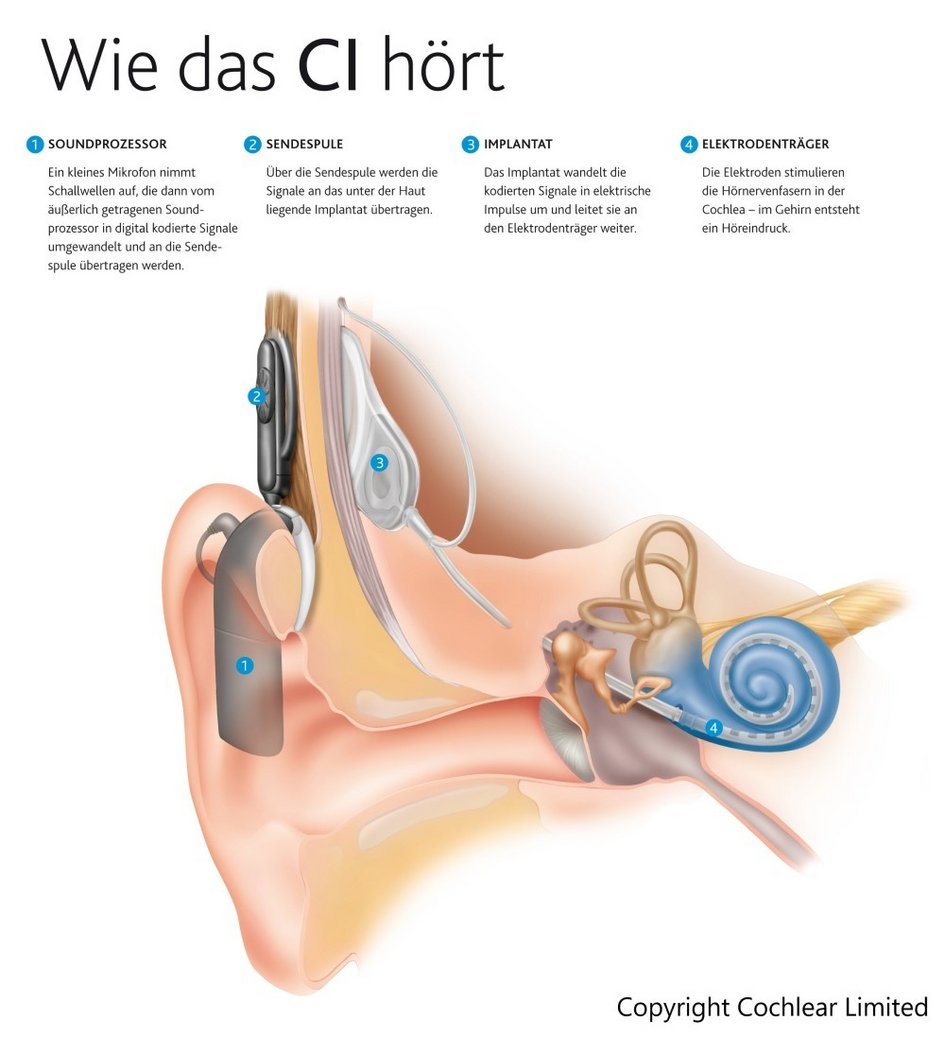
Für die Beschreibung eines CI-Systems kann man eine Unterscheidung in zwei wesentliche Bestandteile vornehmen: Ein Soundprozessor mit Sendespule an Ohr und Kopf des Patienten und das Implantat unter der Haut. Bei den Prozessoren unterscheidet man zwischen am Kopf getragenen und HdO-Spoundprozessoren (Hinter-dem-Ohr). Dieser ist meist mit zwei Mikrofonen ausgestattet, um Hintergrundgeräusche minimieren zu können. Eine Sendespule am Kopf des Patienten sorgt dafür, dass die vom Soundprozessor digital codierten Signale induktiv zur Empfangsspule unter die Haut gelangen. Die so erhaltenen digitalen Informationen werden im Implantat in elektrische Signale umgewandelt. Das elektrische Signal steuert das aus bis zu 22 Elektroden bestehende Elektrodenarray des Cochlea-Implantats an. Dieses Elektrodenarray wird operativ in der Cochlea des Patienten plaziert. Durch die Ansteuerung der Elektroden erfolgt eine Stimulierung der Hörnervenfasern. Daraufhin feuern die Nervenzellen, wodurch Sprache oder Musik wahrgenommen werden können.
Welche Ziele werden mit dem Forschungsprojekt verfolgt?
Im Rahmen des Forschungsprojektes zum Thema Audiocodierungsstrategien für Cochlea-Implantate, sollen die derzeit in Soundprozessoren verwendeten Codierungsstrategien optimiert und neue Strategien erforscht werden.
Damit auch Forscher ohne Zugang zu Patienten ihre Algorithmen testen können, wollen wir eine neue Synthese implementieren, die mit dem Hörempfinden von CI-Patienten korreliert. Dafür wollen wir die Funktionsweise des menschlichen Gehörs als Vorbild nehmen und Faktoren wie Kanalinteraktion und Refraktärzeit bei der Signalsynthese berücksichtigen.
Zur Umsetzung der Patientenlosen Tests entsteht im Sommer 2019 an der Ostfalia Hochschule mit der Renovierung des reflexionsarmen Raumes ein Ort der akustischen Möglichkeiten für vielseitige Test- und Simulationsanwendungen. Ein Anwendungsbeispiel für ein Solches Testvorhaben ist ein automatisierter Hörtest für die Algorithmen von CIs. Darüber hinaus sind auch Messungen für Hörgeräte oder Frequenzgangmessungen und vieles mehr möglich.
Audiocodierungsstrategien
Damit die von einem CI aufgenommenen Schallwellen in ein für unser Gehirn verwertbares Signal transformiert werden können, benötigt es eine Verarbeitung durch Audiocodierungsstrategien. Es gibt verschiedene Ansätze diese Aufgabe zu bewältigen.
Continus Interleaved Sampling (CIS)
Bei der CIS-Strategie [3] werden alle Elektroden in der Cochlea des Patienten einzeln angesteuert. Das bedeutet, dass immer nur eine Elektrode mit einem Stromimpuls Nervenfasern in der Cochlea stimuliert. Dadurch sollen Interaktionen zwischen benachbarten Elektroden verhindert werden. Zu jedem Zeitpunkt der Pulssequenz ist nur ein Impuls mit einer definierten Pulsbreite gleichzeitig aktiv.

Die wert- und zeitkontinuierlichen Schallwellen werden von einem Mikrofon aufgenommen und mit Hilfe eines A/D-Wandlers in ein digitales, zeit- und wertdiskretes, elektrisches Signal umgewandelt. Anschließend wird das Signal in 22 Kanäle eingeteilt. Diese Einteilung in die verschiedenen Kanäle erfolgt durch eine IIR-Filterbank, die aus 22 Bandpassfiltern besteht. Anschließend wird in dem Block Amplitudenextraktion von dem bandpassgefilterten Zeitsignal die Einhüllende berechnet. Diese wird danach unterabgetastet, so dass es für jeden Impuls einen Amplitudenwert gibt. Mittels einer logarithmischen Kompressionsfunktion wird für die Kanäle der Dynamikbereich der akustischen Amplitude (ca. 30dB bei Sprache) auf ca. 5dB komprimiert und somit an den wahrnehmbaren Dynamikbereich von CI-Trägern angepasst. Dies ist normalerweise ein patientenspezifischer Vorgang. Zum Schluss wird die komprimierte Einhüllende mit den Impulsen moduliert und an die Elektroden gesendet.
Die CI-Strategie kann um virtuelle Kanäle erweitert werden. Dies wird durch den blauen Pfad im Blockschaltbild dargestellt. Durch virtuelle Kanäle kann die Freuqenzauflösung bis zu einem gewissen Grad erhöht werden.

Psychoacoustic Advanced Combinational Encoder (PACE)
Bei der PACE-Strategie [4] wird mit Hilfe eines psychoakustischen Modells bestimmt, welche Elektroden aktiviert werden. Simultan zur Vorgehensweise des CIS-Algorithmus, werden die Schallwellen zunächst diskretisiert. Anschließend wird das digitale Audiosignal mit einer FFT-Filterbank in 22 Kanäle zerlegt. Auch der Block Amplitudenextraktion funktioniert wie in CIS beschrieben. Danach werden mit dem psychoakustischen Modell die Kanäle selektiert, deren Informationsgehalt für das menschliche Gehör am höchsten ist. Als Kriterium dafür wird die spektrale Maskierung berücksichtigt.
Eine Darstellung dieser Kanalselektion bringt Aufschluss über die Wirkungsweise der Maskierung. Die Schwarz markierten Kanäle werden vom Algorithmus ausgewählt. Es ist zu sehen, dass einige Kanäle trotz einer hohen Amplitude nicht ausgewählt werden. Der Grund dafür ist, dass die Kanäle von den bereits ausgewählten Kanälen maskiert wurden und dadurch nicht mehr von Menschen wahrnehmbar sind. Man nennt dieses Vorgehen auch Maskierungseffekt oder Verdeckung. Nachdem die Kanäle ausgewählt wurden, werden die Amplituden wie bei der CIS-Strategie komprimiert, mit elektischen Impulsen moduliert und an das Elektrodenarray gesendet. Auch bei dieser Strategie kann das Modell um virtuelle Kanäle erweitert werden. Dies ist mit dem blauen Pfad im obigen Blockschaltbild dargestellt.
Virtuelle Kanäle
Durch die Anzahl an Elektroden ist die spektrale Auflösung stark limitiert. Trotz dieser Limitierung ist es Cochlea-Implantat-Trägern möglich, Sprache in ruhiger Umgebung zu verstehen. Gibt es allerdings viele Nebengeräusche, wie z.B. in einer Bar, ist eine höhere spektrale Auflösung hilfreich. Die Erkennung von Instrumenten und die Wahrnehmenung von Melodien ist ebenfalls nur mit einer erhöhten spektralen Auflösung möglich. Townshend et al. [5] berichteten 1987, dass zusätzliche Tonhöhen von Patienten wahrgenommen werden, wenn zwei benachbarte Elektroden gleichzeitig angesteuert werden. Welche Tonhöhe wahrgenommen wird, kann durch den Strom, der durch die Elektroden fließt, gesteuert werden. Die wahrgenommene Lautstärke bleibt dabei gleich, solange die Summe der durch die beiden Elektroden fließenden Ströme konstant ist [6].

Vocoder
Ein Vocoder bietet die Möglichkeit die elektrischen Impulse des Elektrodenarrays in ein hörbares Audiosignal zun transformieren. die sinusoidale Synthese ist ein Verfahren für die Realisierung des Vocoders. Hierbei wird für jede Elektrode ein Sinussignal erzeugt, dessen Frequenz gleich der Mittenfrequenz des entsprechenden Bandes ist. Jedes dieser Signale wird mit der Amplitude des Impulses der zugehörigen Elektrode moduliert. Anschließend wird die Summe aller Sinussignale berechnet. Dadurch entsteht ein Audiosignal, welches für Normalhörende hörbar ist. Da die Verarbeitung frameweise stattfindet, muss zwischen den Frames sowohl die amplitude, als auch die Frequenz interpoliert werden, um Sprünge im Audiosignal zu vermeiden.
Die Erzeugung eines Audiosignals basiert bei diesem Vocoder im Wesentlichen auf den Amplituden der Impulse. Effekte, die durch die Änderung der Impulsrate auftreten, werden nicht berücksichtigt. Dafür bedarf es eines Vocoders, der wichtige Eigenschaften des Gehörs einberechnet. Mit dem modifizierten Vocoder kann bei Tests mit Normalhörenden das Hörempfinden mit dem von Cochlea-Implantat-Trägern stark korrelieren.
Um dieses Ziel zu erreichen, soll eine Vorstufe vor den zurzeit genutzten Vocoder geschaltet werden. Diese sollte das, durch die Impulse, sich ausbreitende elektrische Feld simulieren. Dadurch kann bestimmt werden, in welchem Bereich der Cochlea Hörnerven durch einen Impuls aktiviert werden. So wird das Übersprechen von Elektroden berücksichtigt. Außerdem ist das Einbeziehen der Refraktärzeit (Erholungszeit) der Hörnerven sinnvoll. Durch diese Erweiterung ist es möglich, dass Hörnerven trotz eines elektrischen Impulses nicht aktiviert werden, da sie sich noch vor der vorherigen Aktivierung erholen müssen. Die Veränderung der Tonhöhe sowie die der Lautstärke in Abhängigkeit der Impulsrate ist ebenfalls ein wichtiger Mechanismus, der berücksichtigt werden muss. Eine ähnliche Vorstufe wurde in [9] beschrieben und realisiert.
Reflexionsarmer Freifeldraum
In dem reflexionsarmen Freifeldraum der Hochschule sollen sowohl subjektive Hörtests mit Probanden als auch automatisierte Sprachverständlichkeitstests durchgeführt werden. Dafür wird ein 8-Kanaliges Lautsprechersystem aufgebaut. Mit diesem System wird ein Kunstkopf beschallt, in dessen Ohren Mikrofone mit Ohrsimulatoren verbaut sind. Das von diesen Mikrofonen aufgenommene Signal wird anschließend mit einer Spracherkennung analysiert. So können Sprachverständlichkeitstests automatisch durchgeführt werden. Der Vorteil dieses Systems liegt darin, dass neue oder modifizierte Algorithmen zunächst ohne Probanden getestet werden können. Wenn der Test erfolgreich war, können anschließend subjektive Tests mit Probanden durchgeführt werden.
Literatur
[1] D. S. Dalton et al., „The impact of hearing loss on quality of life in older adults“ (eng), The Gerontologist, Jg. 43, Nr. 5, S. 661–668, 2003.
[2] L. Roland et al., „Quality of Life in Children with Hearing Impairment: Systematic Review and Meta-analysis“ (eng), Otolaryngology--head and neck surgery : official journal of American Academy of Otolaryngology-Head and Neck Surgery, Jg. 155, Nr. 2, S. 208–219, 2016.
[3] B. S. Wilson et al., „Better speech recognition with cochlear implants“ (eng), Nature, Jg. 352, Nr. 6332, S. 236–238, 1991.
[4] W. Nogueira, A. Büchner, T. Lenarz und B. Edler, „A Psychoacoustic “NofM”-Type Speech Coding Strategy for Cochlear Implants“, EURASIP Journal on Applied Signal Processing, S. 3044–3059, 2005.
[5] B. Townshend, N. Cotter, D. van Compernolle und R. L. White, „ Pitch perception by cochlear implant subjects“ (eng), The Journal of the Acoustical Society of America, Jg. 82, Nr. 1, S. 106–115, 1987.
[6] Advanced Bionics, „HiRes Fidelity 120 Sound Processing: Implementing Active Current Steering for Increased Spectral Resolution in Harmony HiResolution Bionic Ear Users“, 2009.
Packet Loss Concealment (PLC)
Packet Loss Concealment (PLC)
In paketvermittelnden Netzen - wie insbesondere dem Internet - werden zunehmend auch Audiodaten übertragen. Typische Anwendungen sind z.B. Real-Time-Streaming oder VoIP. Diese basieren i.A. auf dem unzuverlässigen Datagram-Service UDP, um Verzögerungen durch erneute Übertragung von verlorenen Paketen (wie bei TCP) zu vermeiden.
Die UDP- und RTP-Internet-Protokolle bieten keine Möglichkeit, eine fehlerfreie Übertragung von Paketen für Echtzeitdienste wie Audio oder Sprache zu garantieren. Es entstehen Paketverluste, welche die Dienstqualität beeinträchtigen und einen Qualitätsverlust der Audiodaten verursachen.

Mit Hilfe von geeigneten PLC- (Packet Loss Recovery) Verfahren können die bei paketorientierter Übertragung von Audiosignalen durch Paketverluste hervorgerufenen Störeffekte reduziert oder gar behoben werden.
Für die Verdeckung einer Lücke, die auf einen Paketverlust während der Übertragung zurückzuführen ist, ist eine weitgehende Parametrisierung, Analyse und darauf beruhende Inter- bzw. Extrapolation des Audiosignals erforderlich. Die Signalbehandlung erfolgt sowohl im Zeit- als auch im Frequenzbereich.
Audiomessung im reflexionsarmen Raum

Anwendungen
Im reflexionsarmen Freifeldraum der Hochschule können sowohl subjektive Hörtests mit Probanden, als auch automatisierte Sprachverständlichkeitstests durchgeführt werden. Dafür werden Testsätze über Lautsprecher ausgegeben und mit den im Kunstkopf befindlichen Ohrsimulatoren aufgenommen. Das aufgenommene Signal wird anschließend mit einer Spracherkennungssoftware analysiert. So können Sprachverständlichkeitstests und andere Messungen automatisch durchgeführt werden. Der Vorteil dieses Systems liegt darin, dass neue oder modifizierte Algorithmen zunächst ohne Probanden getestet werden können. Wenn der Test erfolgreich war, können anschließend subjektive Tests mit Probanden durchgeführt werden.
Hintergrund
Der reflexionsarme Raum ist ein spezieller Raum zur Durchführung akustischer Messungen. Wände, Boden und Decke sind mit Schallabsorbern bestückt, durch die Reflexionen fast vollständig eliminiert werden. Die dadurch entstehenden akustischen Eigenschaften des Raums ermöglichen bzw. begünstigen verschiedene akustische Messungen. Im Sommer 2019 wurde der reflexionsarme Raum der Ostfalia Hochschule neuausgekleidet und mit moderner Technik ausgestattet. Der Raum erfüllt die Anforderungen der DIN ISO 3745. Er hat eine begehbare Fläche von 5,38m x 5,59m und ist 2,3m hoch. In einem separatem Raum befindet sich die Technik zur Steuerung der Messungen.
Ausstattung
Für die verschiedenen Messungen im Rahmen von Arbeiten in der Ostfalia Hochschule stehen verschiedene Messgeräte zur Verfügung. Mit dem Kunstkopf und den Ohrsimulatoren können binaurale Tonaufnahmen durchgeführt werden.

Für die Beschallung eines DUT aus verschiedenen Richtungen stehen acht Lautsprecher sowie ein programmierbarer Drehtisch zur Verfügung.

Gesteuert werden die Messungen von einem separaten Raum aus. Mit einem Audiointerface können die Lautsprecher einzeln angesteuert und die Mikrofonsignale aufgenommen werden. Des Weiteren steht ein Messsystem der Firma HEAD acoustics GmbH bestehend aus MFE VI.1, labBGN sowie der entsprechenden Software zur Verfügung.

Mit dem SQobold der Firma HEAD acoustics GmbH steht außerdem ein mobiles Aufnahme- und Wiedergabegerät zur Verfügung, mit dem binaurale Aufnahmen auch außerhalb des Raumes erstellt werden können.